Masstree: A cache-friendly mashup of tries and B-trees
Cache Craftiness for Fast Multicore Key-Value Storage Mao et. al., EuroSys 2012 [code]
The Big Idea
Consider the problem of storing, in memory, millions of (key, value) pairs, where key is a
variable-length string. If we just wanted to support point lookup, we’d use a hash table. But
assuming we want to support range queries, some kind of tree structure is probably required. One
candidate might be a traditional B+-tree.
In such a B+-tree, the number of levels of the tree are kept small thanks to the fact that each node has a high fan-out. However, that means that a large number of keys are packed into a single node, and so there’s still a large number of key comparisons to perform when searching through the tree.
This is further exacerbated by variable-length keys (e.g. strings), where the cost of key comparisons can be quite high. If the keys are really long they can each occupy multiple cache lines, and so comparing two of them can really mess up your cache locality.
This paper proposes an efficient tree data structure that relies on splitting variable length keys into a variable number of fixed-length keys called slices. As you go down the tree, you compare the first slice of each key, then the second, then the third and so on, but each comparision has constant cost.
For example, think about the string the quick brown fox jumps over the lazy dog. This string
consists of the following 8-byte slices: the quic, k brown_, fox jump, s over t, he lazy_
and finally dog. To find a string in a tree, you can look for all strings that match the first
slice first, and then look for the second slice only in strings that matched the first slice, and so
on - only comparing a fixed size subset of the key at any time. This is much more efficient than
comparing long strings to one another over and over again. The trick is to design a structure that
takes advantage of the cache benefits of doing these fixed-size comparisons, without losing a
tradeoff based on the large cardinality of the slice ‘alphabet’. Enter the Masstree.
Masstrees: a mashup of tries and B+-trees
Splitting keys into fixed length strings means that you can view a string as a concatenation of ‘letters` drawn from a very large alphabet (of 8-byte strings). A natural search structure for variable-length strings over a fixed alphabet is a trie. The problem is that a trie formed by splitting up strings into their natural one-character alphabet would be too deep when you’ve got lots of long keys (a trie is linear in the size of the key). Even if we reduced the string length by a constant factor by splitting the string into larger slices, the trie becomes very hard to implement because at each node you could have \(256^k\) next nodes to choose from if your slice is \(k\) bytes long. The child pointers in an English alphabet trie are usually just stored in an array indexed by the next character you’re looking for (because here \(k=1\), and we can afford 256 pointers per node). That’s obviously impossible with large alphabets.
So we need a data structure that allows us to index amongst \(256^k\) possible next-hops very efficiently. Here we can use our friend the B+-tree! The idea is to make each node in the trie its own B+-tree. When compared to tries, B+-trees are great at compactly representing their child pointers by using ranges; in doing so they give up the ability to be indexed in constant time but instead take logarithmic time to search. At any trie node’s B+-tree, we are looking only for a fixed ‘slice’ (or letter, in the 8-byte alphabet) - searching for it tells us the B+-tree to look in for the next slice in the key.
The structure that results from implementing this scheme is called a Masstree. The paper describes it as a “trie-like concatentation of B+-trees”. Each level of the trie is a ‘layer’.
“The trie structure efficiently supports long keys with shared prefixes; the B+-tree structures efficiently support short keys and fine-grained concurrency, and their medium fanout uses cache lines effectively.”
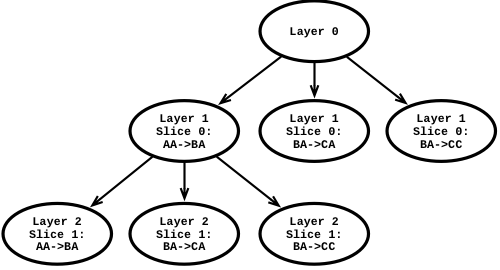
Masstree as a trie (2-byte slices)
In the above diagram, the string CCAA would be found in the Layer 1 / Slice 0: BA->CC node. The
string AABBCC would be found in the node Layer 2 / Slice 1: BA->CC.
Masstree vs B+-trees
If you don’t include the entire key in every node, the resulting tree naturally has to be deeper. So aren’t masstrees going to be less efficient for searching for keys?
More specifically: imagine storing \(N\) keys of length \(l\). A balanced B+-tree will have a depth of \(O(log N)\). A masstree will divide those keys into slices of length \(k\), so will consist of \(l/k\) trees, each of which could have height up to \(log(N)\). So the total height of a masstree is \(O(l.log(N))\).
But here’s the difference - a masstree will do fixed cost comparisons at each level, since the length of each slice is fixed. A B+-tree, on the other hand, has to compare the entire key every time; since the key length is \(l\) that means the total comparison cost is also \(O(l.log(N))\).
In the case where strings share common prefixes (for example, URLs), the first few levels of a
masstree are going to be basically constant in size (because the first 8-byte slice of
http://www.google.com is http://w, which is common to millions of websites). In the limit, only
the last constant number of layers will have entries proportional to the number of strings in the
database, when the strings have divergent suffixes. In this case, the cost of searching a masstree
drops to \(O(l + log(N))\) (but a straight B+-tree will still have \(O(l.log(N))\) cost).
Implementation details
A masstree is implemented almost like a regular B+-tree. The differences are that the subset of the key to be compared changes as you go down the tree, and that leaf nodes may contain either pointers to values (as is traditional in a B+-tree), or to the next layer.
Border nodes (i.e. leaves that may point to other B+-trees) have sibling links to support efficient range queries.
Much of the interesting implementation detail is around concurrency control (see sections 4.4, 4.5 and 4.6). Masstree is designed to support high-throughput concurrent access without sharding. Some notes from their approach:
Concurrency
- Readers never lose updates: will always see a real recent value and not time-travel.
- Writers lock each other out, because the cost of an uncontended lock is roughly the same as a compare-and-swap, and locks are only held for a short time (because presumably all nodes are in memory).
- Readers are always optimistic, and may retry if they read a node that is being modified.
- There is a concurrent
deleteimplementation (which many B+-trees lack).
Permutations
- In border nodes, keys are stored out-of-order in an array, and a separate
permutationarray is maintained to track the mapping fromkeys[i]to thei^thkey’s position in the sorted keys array. - The permutation fits inside a 64-bit integer, and so can be written atomically. This means that inserting a key into the middle of the existing keys in sorted order can be done by a) adding the key to the end of the unsorted array b) rewriting the permutation locally and then c) publishing the permutation by writing it back, so that other readers and writers can see it.
- During the above process, no invalid intermediate state can be observed; writing the permutation is an atomic linearization point (not an ‘unholy mess’ :)).
What about the so-called ‘cache craftiness’?
“First, Masstree must efficiently support many key distributions, including variable-length binary keys where many keys might have long common prefixes. Second, for high performance and scalability, Masstree must allow fine-grained concurrent access, and its get operations must never dirty shared cache lines by writing shared data structures. Third, Masstree’s layout must support prefetching and collocate important in- formation on small numbers of cache lines. The second and third properties together constitute cache craftiness.”
- Fixed-size key comparisons can be done with SIMD (not mentioned by paper, maybe not a win)
- Border nodes are 256-bytes, so fit in four cache lines (much of that is key / value data).
- Linear search through the set of keys therefore exhibits good cache locality.
- Prefetching an entire node overlaps search computation with memory delays and helps with throughput.
- Get operations indeed do not dirty any shared state.
Evaluation
Most interesting is the factor analysis that shows what happens if you compare Masstree to a system where one of the requirements is relaxed. Doing so shows the cost of implementing that requirement in masstree:
- Compared to a B+-tree supporting only fixed-size keys, masstrees are about 1% slower
- Keys with common prefixes maintain high throughput even though masstrees may become ‘superficially’ imbalanced.
- Range queries appear to be inherently expensive - masstrees are 2.5x slower than a straight hash table.
“Masstree’s performance is dominated by the latency of fetching tree nodes from DRAM”
More nodes are fetched for a masstree than a B+-tree, but each B+-tree node is fatter due to the larger keys, so it may be a wash.
Comments
- In-memory only - the increased depth of the tree presumably mitigates a lot of the benefits of a masstree since the stall time for a fetch is so much higher.
- It seems quite hard to fill up a masstree - you would need to have strings that diverge from each other at every ‘slice’. I wonder if in practice there are usually some layers that are fairly empty and therefore the search cost is better than the upper bound in many cases.
- Interior and border nodes have different sizes, so why the same fanout?
- How much worse (or better?) is this than a B+-tree when the dataset exceeds main memory capacity? More expensive fetches (and more of them) should make masstrees slower.